비동기 프로그래밍에 대해 공부를 하다보니 굉장히 멀리 오게 되었고, 그래서 하나씩 정리를 하려고 합니다. bottom-up 방식으로 작성하여 첫 게시글인 캐시 메모리에서부터 가장 고단위인 코루틴까지 작성할 예정입니다.
캐시 메모리
캐시 메모리에 대해 모든 내용을 작성하기 보다는, 비동기 프로그래밍을 이해하는 것에 필요한 내용 위주로 정리하였습니다.
데이터 지역성
캐시 메모리는 데이터의 지역성을 이용하여 처리 속도를 높입니다. 캐시 메모리가 가져오는 데이터는 프로세서에서 자주 쓰이는 데이터여야 합니다. 한 번만 쓰고 다시 다른 데이터를 불러온다면, 그냥 저장소에서 바로 가져오는 것이 여러 중간단계를 거치는 것보다 더 빠를 것입니다. 캐시 메모리에 쓰이는 데이터는 프로세서에서 자주 접근하는 데이터로 구성해야 이득을 얻을 수 있을텐데, 그 데이터를 어떻게 알 수 있을까요?
자주 사용하는 데이터는 데이터 지역성의 원리를 따릅니다. 시간 지역성과 공간 지역성으로 나누어서 볼 수 있습니다.
시간 지역성은 최근 접근한 데이터에 다시 접근할 확률이 높다는 것을 의미합니다. 예를 들어 반복문에서 같은 변수에 여러 번 접근하는 경우가 있습니다.
공간 지역성은 최근 접근한 데이터의 주변 데이터에 다시 접근할 확률이 높다는 것을 의미합니다. 배열은 연속적으로 할당되기에, 특정 배열의 데이터들을 접근한다면 공간적으로 연속된 데이터들에 접근하는 것을 의미합니다.
1
for(i in 1..100) {arr[i] = i}
위의 반복문에서 변수 i가 호출되는 것은 시간 지역성을 의미하며, arr[i]에서 배열의 원소를 연속적으로 호출하는 것은 공간 지역성을 의미합니다.
캐시 메모리의 구조
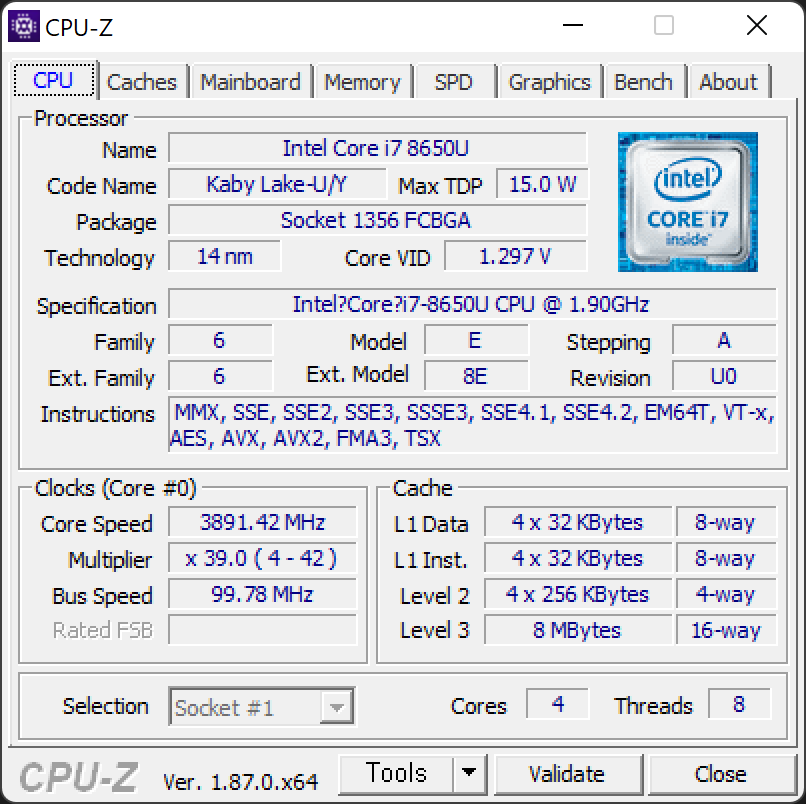
프로세서마다 차이가 있지만, 많은 프로세서에서 각 코어마다 L1 캐시와 L2 캐시를 가지고, 모든 코어가 공유하는 L3 캐시를 둡니다. 위 자료의 오른쪽 하단에서 L1과 L2에는 앞에 4X라고 표시된 것이 4개가 장착되었다는 것으로 4코어 프로세서인 i7-8650U의 각 코어에 할당된 것입니다. 그리고 L3 캐시는 별다른 표시가 없으므로 하나만 존재한다는 것을 알 수 있습니다.
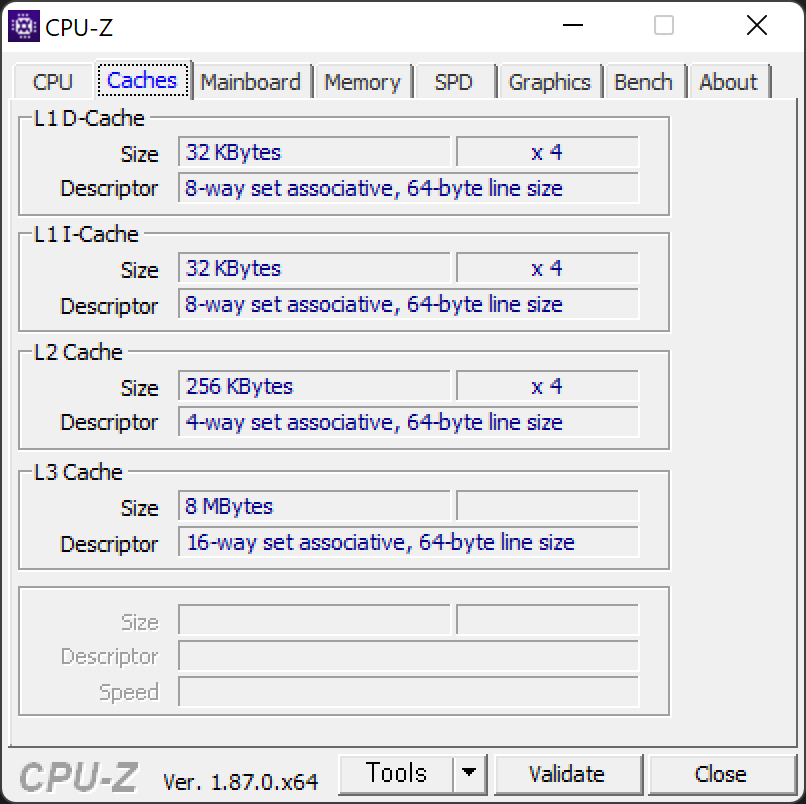
8-way set associative, 64-byte line size는 캐시 라인의 크기와, 캐시 매핑 정책에 대한 것입니다.
프로세서가 한 사이클에 처리할 수 있는 단위인 워드 몇 개를 묶어 하나의 캐시 라인(캐시 블록)이라고 합니다. line size는 캐시 라인의 크기를 의미하며, 64byte는 64bit의 워드 8개가 묶인 것으로 이해할 수 있습니다. 캐시의 데이터를 교체할 때는 특정 워드 하나만 교체할 수 없으며, 캐시 라인 전체를 교체해야 합니다. 그 이유는 캐시 데이터 교체에는 비용이 드는데, 공간 지역성을 생각하면 인접한 데이터들도 사용될 확률이 높기 때문에 함께 가져오는 것으로 이해할 수 있습니다.
주 메모리 등에서 캐시 라인을 가져와 캐시에 저장할 때 캐시 라인의 데이터를 식별하기 위한 태그 비트와 캐시 라인의 유효성을 검증하기 위한 유효 비트를 포함하여 하나의 캐시 엔트리가 완성됩니다.
그렇다면 캐시 엔트리는 캐시 메모리 공간 중 어디에 배치되어야 할까요? 8-way set associative가 바로 그 내용을 담고 있습니다.
캐시 배치 정책
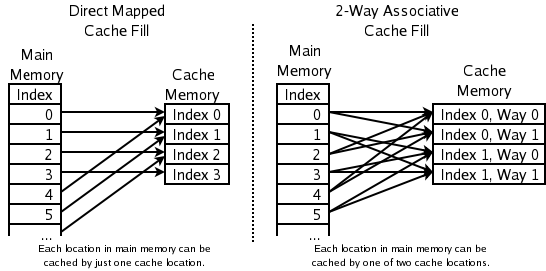
(출처: By Hellisp - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=851638)
Direct Mapped Cache 방식에서는 캐시 메모리의 각 주소마다 저장될 메인 메모리의 주소가 정해져 있습니다. 캐시 메모리의 크기보다 메인 메모리의 크기가 훨씬 크기 때문에, 하나의 캐시 메모리 주소에 할당된 메인 메모리 주소가 많을 것입니다. 하지만 하나의 캐시 메모리 주소에 들어갈 수 있는 데이터는 하나의 메인 메모리 주소에 해당하는 데이터만 가능하기 때문에 같은 메모리 주소에 해당하는 메인 메모리의 주소를 여러 개 호출할 경우 바로 캐시 미스가 발생한다는 단점이 있습니다.
이 방법은 이상적인 경우 겹치는 주소가 하나도 없이 모든 캐시 메모리 공간에 배치되지만, 최악의 경우에는 하나의 캐시 메모리 주소에 서로 다른 메인 메모리 주소들이 계속 갱신되어 계속 캐시 미스가 발생할 수 있을 것입니다. 이렇게 캐시 미스가 발생할 확률이 꽤 높기 때문에 현재 쓰이는 방식은 아닙니다.
다음으로 Fully Associative Cache 방식이 있습니다. 이 방식은 비어있는 캐시 메모리 주소가 있으면 바로 저장합니다. 저장할 때도 쉬워보이고, 캐시 미스가 발생할 확률도 위의 Direct Mapped Cache 방식에 비하면 매우 적어보입니다. 하지만 캐시 메모리에서 필요한 데이터를 찾기 위해서는 일일히 검색해야 하기 때문에 시간이 오래 걸릴 것입니다. 따라서 이 방법도 거의 쓰이지 않습니다.
그렇다면 이 두 방식을 적절히 섞는 것은 어떨까요? Set Associative Cache 방식은 Direct Mapped Cache 처럼 메인 메모리 주소에 해당하는 캐시 메모리 주소를 두되, 그 주소에 들어갈 수 있는 메인 메모리 주소를 하나가 아니라 여러 개를 두고 그 중 비어 있는 곳에 Fully Associative Cache 처럼 저장하는 방식입니다.
8-way set associative는 특정 주소마다 8개의 캐시 엔트리를 저장하는 방식이라는 의미입니다.
캐시 교체 정책
캐시 메모리의 공간은 한정되어 있고 메인 메모리에 비하면 매우 작은 크기이기 때문에 빠른 시간에 모든 공간에 데이터가 차게 될 것입니다. 예를 들어 위에서 8-way set associative의 경우 8개의 캐시 엔트리를 모두 채운 이후에 새로운 데이터를 캐시에 저장하고 싶다면 기존의 데이터를 새 데이터로 교체해야 하는데, 어떤 데이터를 교체할 것인지에 대한 수많은 정책들이 있습니다.
그 중에서 많이 쓰이는 방법은 LRU (Least Recently Used), 또는 이에 기반하여 변형된 정책입니다. 주어진 공간이 모두 채워졌을 경우, 가장 이전에 사용된 데이터를 교체하는 방식입니다. 시간 지역성을 고려해보면 최근에 쓰였던 데이터는 다시 쓰일 확률이 높기 때문에 가장 이전에 쓰인 데이터를 교체하는 것으로 이해할 수 있습니다.
이 방식을 고수준 프로그래밍 언어로 구현한다면 Doubly Linked List와 HashMap을 이용하거나, Java와 같은 언어에서는 LinkedHashMap으로 구현할 수 있을 것입니다.
SMP
SMP(Symmetric Multi-Processor, 대칭형 다중 프로세서)
고려해야 할 문제점들
비동기 프로그래밍에서 고려해야 할 문제점들 중에서 위의 내용들과 관련된, 프로세서와 메모리 단계에서 생각해야 할 문제점들이 있습니다. 프로그래머는 아래의 문제점들을 고려하면서 코드를 작성해야 합니다.
비순차적 명령어 처리
우선 프로세서가 들어오는 명령들을 순서대로 실행하지 않는 것이 있습니다. 예를 들어 여러 명령어가 프로세서에 들어 왔을 때 특정 명령어에서 로드한 메모리의 캐시 미스가 발생한다면 다시 데이터를 찾아 교체하는 시간이 필요할 것입니다. 그 동안 프로세서가 아무런 일을 하지 않고 기다리는 대신에, 기다리는 데이터와 관련 없는 다른 명령어가 그 이후에 있다면 그 명령어를 먼저 처리합니다. 또한 멀티스레드가 아니더라도 동시에 처리할 수 있는 명령어들은 동시에 먼저 처리하는 등의 방법으로 프로세서의 효율을 높입니다. 이를 비순차적 명령어 처리라고 합니다.
명령을 처리할 수 있는 코어가 하나인 프로세서이거나, 싱글 스레드로 작성된 프로그램이라면 위와 같이 비순차적으로 명령어를 처리해도 프로그래머 입장에서는 아무런 문제를 느낄 수 없습니다. 그 이유는 명령어 주소를 계산하여 그 주소에서 명령어를 가져오는 인출 단계와 명령어 완료 단계는 순차적으로 진행되기 때문에 결과적으로 작성된 코드가 순서상으로 변화되지 않았기 때문입니다.
하지만 프로세서의 코어가 여러 개이고, 멀티 스레드로 작성된 프로그램이라면 경우가 복잡해집니다. 예를 들어 L3 캐시 또는 메인 메모리에서 데이터를 인출하여 레지스터의 큐에 값을 저장한 동안 다른 코어가 같은 메모리 주소의 데이터를 변경시켰을 수도 있습니다. 하나의 메모리에 접근하고 변경할 수 있는 코어가 여러 개이기 때문에 발생하는 현상인 것입니다. 또한 모바일 프로세서는 대부분 x86이 아닌 ARM인데 저장 명령의 순서가 유지되지 않고, 모든 코어에 저장 명령이 동시에 도달하지 않을 수도 있습니다. 또한 이렇게 순서가 바뀌는 것은 프로세서 뿐만이 아니라 성능 향상을 위해 컴파일러에 의해서도 발생할 수 있습니다.
데이터 경합
여러 스레드에서 같은 데이터에 동시에 접근하고, 데이터를 수정할 때 데이터 경합이 발생합니다.
한 스레드에서 A = 5 로 값을 할당하고, 다른 스레드에서 이 값을 읽는다고 할 때, 어떤 스레드가 먼저 실행될지 알 수 없기 때문에 A의 값이 어떻게 관찰될지 보장할 수 없습니다.
이 문제를 해결하기 위해서는 특정 변수에 대해 여러 스레드가 동시에 접근하는 것을 막거나 데이터의 원자성을 보장해야 하며, 많은 프로그래밍 언어에서 Mutex, Volatile 등의 다양한 방법으로 지원합니다.
가짜 공유
데이터 경합을 막기 위해 락을 사용했다고 가정하면, 락이 걸린 캐시 주소에 해당하는 캐시 라인을 무효화 시킵니다. 위에서 캐시 라인별로 태그 비트가 달린다는 것을 알았기 때문에 왜 캐시 라인 전체가 무효화 되는지는 이해할 수 있을 것입니다.
그런데 여러 코어에서 동시에 같은 캐시 라인에 접근하려고 할 때 이렇게 락이 걸린다면, 안전하지만 성능 저하가 발생할 수 있을 것입니다. 무효화가 풀릴 때까지 다른 코어는 무효화가 풀리기를 기다려야 하기 때문입니다. 그렇다면 병렬적으로 작성된 코드도 실제로는 여러 스레드가 돌아가면서 작업하니 동시성은 만족하지만 병렬성은 달성하지 못하게 될 수도 있습니다.
해결 방법들
이러한 문제들을 해결하기 위해 프로그래밍 언어에서 다양한 기법들을 라이브러리로 제공하고 있습니다. 이에 대한 내용은 이후의 포스트에서 별도로 정리하겠습니다.